

Resumen del proyecto#
Se desarrolla un sistema de segmentación de carreteras en imágenes aéreas de alta resolución sobre un subconjunto del Massachusetts Roads Dataset. El proyecto combina una fase de ingeniería de características clásica con un modelo de segmentación semántica U‑Net, e incluye un análisis comparativo cuantitativo (Dice, IoU) frente a enfoques sin deep learning.

Planteamiento del problema#
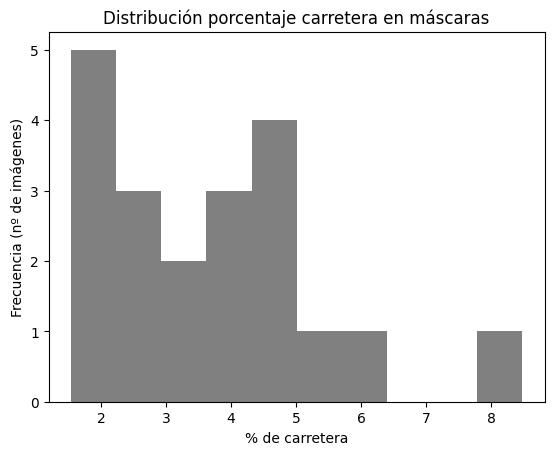
El objetivo es, dada una imagen aérea RGB de tamaño 1500×1500, producir una máscara binaria donde cada píxel se clasifica como “carretera” o “fondo”. Las máscaras de ground truth presentan carreteras muy finas y un fuerte desbalance de clases (alrededor del 3–4 % de píxeles pertenecen a carretera), lo que obliga a cuidar tanto la representación de características como las métricas de evaluación.
- Promedio carretera: 3.70%
- Desviación típica: 1.74%
- Min: 1.54%
- Max: 8.48%
Exploración del dataset y análisis previo#
Se trabaja con 20 pares de imagen satélite + máscara de ground truth, previamente emparejados y verificados. Todas las imágenes comparten resolución y tipos de dato, y el porcentaje de píxeles de carretera se sitúa, de media, en torno al 3–4 %, con variabilidad moderada entre escenas.
A partir de ejemplos representativos se analizan distintos contextos, sobre todo de zonas semi-urbanas con presencia de sombras y vegetación densa, para identificar en qué condiciones el contraste de las carreteras resulta especialmente bajo.


Ingeniería de características clásica#
Análisis de espacios de color#
Como primera etapa se aborda la cuestión de en qué canales de color las carreteras resultan más distinguibles. Para ello se transforman las imágenes RGB a los espacios HSV, LAB, YCrCb y HLS, visualizando sistemáticamente todos sus canales y comparando el contraste carretera/fondo.

De este análisis se observa que:
- Los canales H y S (HSV) y H_hls y S_hls (HLS) son los más eficaces para diferenciar carreteras. b* y Cb podrían ser útiles de forma secundaria. El resto no aporta información relevante.
- Canales como a* o Cr muestran carreteras prácticamente invisibles y se descartan.
Umbralización adaptada al histograma#
Sobre los canales más prometedores se exploran umbrales dependientes del histograma, generando para cada canal:
- Un histograma de intensidades.
- Un conjunto de umbrales en un rango de percentiles relevantes.
- Las máscaras binarias resultantes para cada valor de umbral.
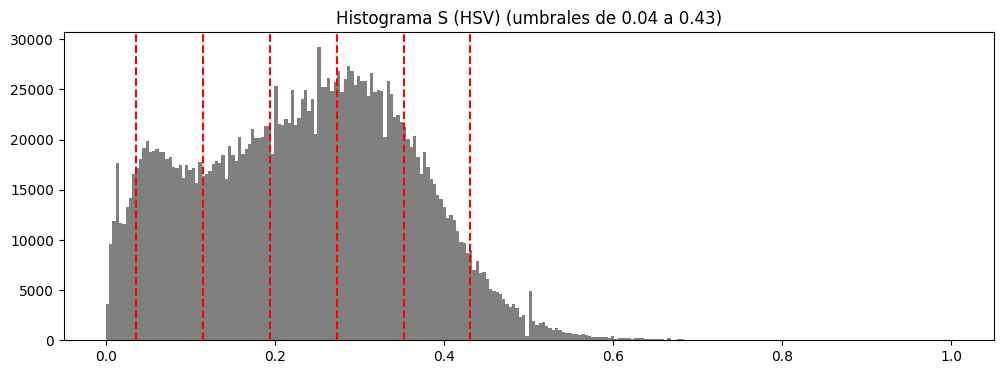

Este estudio permite fijar umbrales concretos, por ejemplo:
- S (HSV) ≈ 0.11
- S_hls (HLS) ≈ 0.08
- b* (LAB) ≈ 0.51
- Cb (YCrCb) ≈ 0.50
como puntos de partida adecuados para construir máscaras binarias.
Operadores morfológicos y limpieza#
Las máscaras binarias iniciales se refinan mediante operadores morfológicos (cierre, apertura) y funciones de eliminación de objetos pequeños y huecos, con el objetivo de:
- Conectar fragmentos de carreteras.
- Eliminar ruido aislado y pequeñas regiones espurias.
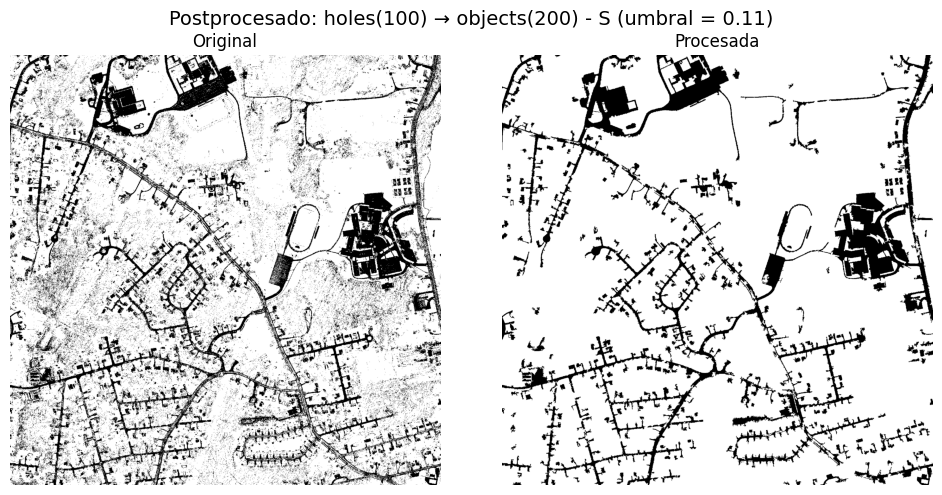
El resultado son máscaras donde la red viaria aparece más continua y con menos ruido, tanto en canales donde las carreteras son oscuras como donde son claras.
Fusión lógica de máscaras#
Se prueban combinaciones lógicas (AND, OR, voto por mayoría) entre las mejores máscaras (S, S_hls, b*, Cb), tanto en su versión original como postprocesada, buscando reforzar la información consistente entre canales y reducir ruido específico de cada uno.
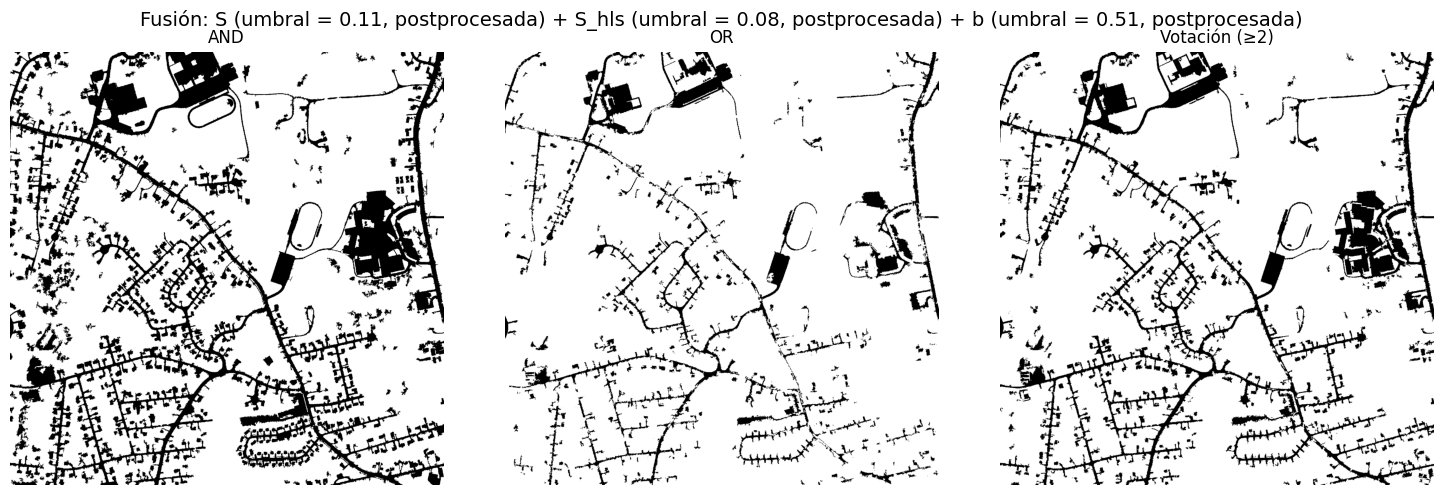
En particular, la fusión AND de las máscaras oscuras postprocesadas (S, S_hls, b*) produce una red de carreteras muy limpia, aunque la mejora cuantitativa frente a la mejor máscara individual es limitada.
Gradientes, contornos y umbralización adaptativa adicional#
Se evalúa el uso de operadores de borde (Sobel, Laplaciano, Canny) directamente sobre las máscaras, así como umbralización adaptativa con diferentes tamaños de bloque y valores de C.


Las principales observaciones son:
Sobel y Laplaciano aportan información complementaria a las máscaras binarias en canales concretos, capturando estructuras más finas; en particular, resultan útiles la magnitud de Sobel y la dirección del Laplaciano (ksize = 5) sobre S y b* postprocesadas.
Canny permite identificar la red viaria, pero introduce una cantidad de ruido excesiva para el objetivo de segmentación fina.
La umbralización adaptativa es especialmente efectiva en canales de tono claro (H, H_hls, Cb), donde reduce notablemente el ruido y genera componentes conexas de carreteras bien definidas; en canales de tono oscuro, las mejoras son más limitadas y dependientes del canal.
Mejor resultado clásico sin aprendizaje profundo#
Combinando:
- Canales cromáticos seleccionados (S, b*, Cb),
- Umbralización fija ajustada,
- Postprocesado morfológico,
se obtiene una segmentación visualmente razonable, pero sensiblemente alejada del ground truth cuando se mide con métricas estrictas como Dice o IoU.

Pipeline de segmentación con U‑Net#
Construcción del volumen de características#
En lugar de utilizar únicamente la imagen RGB, se construye un volumen de 17 canales por imagen, donde cada canal corresponde a una característica específica:
- Canales RGB normalizados (R, G, B).
- Máscaras binarias y postprocesadas de S, b* y Cb.
- Derivadas (magnitud de Sobel, dirección de Laplaciano).
- Versiones con umbralización adaptativa.

Todas las características se reescalan y redimensionan a 256×256 para hacer viable el entrenamiento en GPU/CPU de propósito general.
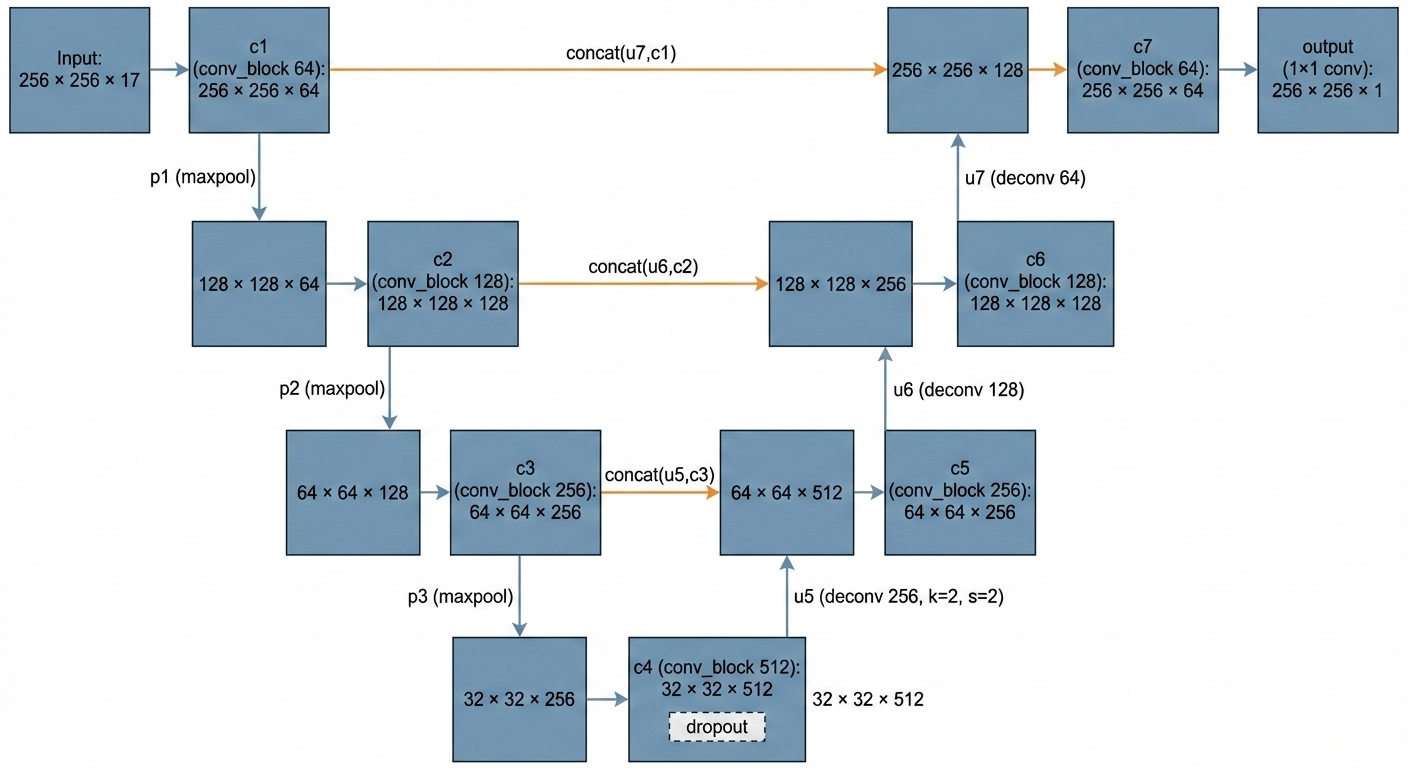
Arquitectura de la U‑Net#
El modelo de segmentación se basa en una U‑Net con:
- Encoder con bloques convolucionales a 64, 128 y 256 filtros.
- Bottleneck con 512 filtros y
Dropout. - Decoder simétrico con capas de
Conv2DTransposey skip connections desde el encoder. - Capa de salida
Conv2D(1, 1)con activación sigmoide para producir una probabilidad por píxel.
Función de pérdida y métricas#
Dado el fuerte desbalance entre fondo y carretera, la función de pérdida elegida combina:
Binary Crossentropy (BCE), que controla el error píxel a píxel:
$$ \mathcal{L}{\text{BCE}}(y, \hat{y}) = - \frac{1}{N} \sum{i=1}^{N} \left[ y_i \log(\hat{y}_i) + (1 - y_i)\log(1 - \hat{y}_i) \right] $$
Dice Loss, que penaliza la falta de solapamiento entre predicción y ground truth:
$$ \mathcal{L}{\text{Dice}}(y, \hat{y}) = 1 - \frac{2 \sum{i=1}^{N} y_i \hat{y}i + \varepsilon}{\sum{i=1}^{N} y_i + \sum_{i=1}^{N} \hat{y}_i + \varepsilon} $$
La función de pérdida total se define como:
$$ \mathcal{L} = \mathcal{L}{\text{BCE}} + \mathcal{L}{\text{Dice}} $$
Como métricas de evaluación se emplean:
Dice coefficient:
$$ \text{Dice}(y, \hat{y}) = \frac{2 \sum_{i=1}^{N} y_i \hat{y}i}{\sum{i=1}^{N} y_i + \sum_{i=1}^{N} \hat{y}_i} $$
IoU (Jaccard index):
$$ \text{IoU}(y, \hat{y}) = \frac{\sum_{i=1}^{N} y_i \hat{y}i}{\sum{i=1}^{N} y_i + \sum_{i=1}^{N} \hat{y}i - \sum{i=1}^{N} y_i \hat{y}_i} $$
Entrenamiento, validación y resultados#
El conjunto de datos se divide en subconjuntos de entrenamiento y validación. Para mejorar la capacidad de generalización se aplica data augmentation con transformaciones geométricas y fotométricas (rotaciones, flips, cambios de brillo/contraste, blur, ruido, deformaciones elásticas).
Se utiliza early stopping monitorizando la pérdida de validación para evitar sobreajuste y seleccionar el mejor modelo.
En términos cuantitativos, sobre las 20 imágenes se obtienen aproximadamente:
- Dice promedio (U‑Net): ≈ 0.69
- IoU promedio (U‑Net): ≈ 0.53
- Dice promedio (mejor método clásico): ≈ 0.34
- IoU promedio (mejor método clásico): ≈ 0.21
Visualmente, la U‑Net genera máscaras más continuas, con mejor alineación de la red de carreteras y mayor capacidad para rellenar tramos débiles o parcialmente ocultos.


Conclusiones y aportaciones#
- El pipeline de ingeniería de características clásica (espacios de color, umbralización, morfología, fusión de máscaras) proporciona segmentaciones interpretables y sirve como base sólida para entender el problema.
- No obstante, cuando se exige una aproximación cuantitativa cercana al ground truth, la U‑Net entrenada sobre un volumen de características enriquecidas ofrece una mejora clara tanto en Dice como en IoU.
- El enfoque se centra en la explicabilidad: cada canal del volumen de entrada corresponde a una transformación visualmente interpretable, lo que facilita el análisis de errores y la discusión técnica con perfiles tanto de ingeniería como de gestión.
Stack tecnológico y organización#
- Lenguaje y librerías: Python 3.12, NumPy, SciPy, scikit-image, OpenCV, TensorFlow/Keras, Albumentations, Matplotlib.